Oracle Interview Questions-Part-1 [Basic questions]
Some basic useful Oracle Interview Questions-Part-1
DDL
Data Definition Language (DDL) statements are used to define the database structure or schema. Some examples:
The attributes are:



Using Cursor For Loop:
The cursor for Loop can be used to process multiple records. There are two benefits with cursor for Loop.


Deletion or Updating Using Cursor: In all the previous examples I explained about how to retrieve data using cursors. Now we will see how to modify or delete rows in a table using cursors. In order to Update or Delete rows, the cursor must be defined with the FOR UPDATE clause.
Explicit Cursors
There are three types of explicit cursor declarations
SELECT company_id FROM company;
SELECT name FROM company
WHERE company_id = id_in;
An Exception is an error situation, which arises during program execution.
When an error occurs exception is raised, normal execution is terminated and control transfers to exception-handling part. Exception handlers are routines written to handle the exception. The exceptions can be internally defined (system-defined or pre-defined) or User-defined exception.
Predefined exception is raised automatically whenever there is a violation of Oracle coding rules.
Predefined exceptions are those like ZERO_DIVIDE, which is raised automatically when we try to divide a number by zero. Other built-in exceptions are given below.
You can handle unexpected Oracle errors using OTHERS handler. It can handle all raised exceptions that are not handled by any other handler.
It must always be written as the last handler in exception block.
The biggest advantage of exception handling is it improves readability and reliability of the code. Errors from many statements of code can be handles with a single handler. Instead of checking for an error at every point we can just add an exception handler and if any exception is raised it is handled by that.
For checking errors at a specific spot it is always better to have those statements in a separate begin – end block.
Examples: Following example gives the usage of ZERO_DIVIDE exception





Example Raising an Application Error With
raise_application_error


------------------------------------------------------------------------------------------------------------
Q: What do you know about sub-queries
Q. Different type of join used in sub-queries
Self join-Its a join foreign key of a table references the same table.
Q. What is difference between TRUNCATE & DELETE ?
Q. Explain Connect by Prior ?
Retrieves rows in hierarchical order
------------------------------------------------------------------------------------------------------------
Q. Difference between SUBSTR and INSTR ?
substr is used to get a sub part of a string but instr is a function that returns the position of a specific character and also according to it's occurrence in that string
------------------------------------------------------------------------------------------------------------
Q. Explain UNION, MINUS, UNION ALL, INTERSECT?
Q. What is ROWID ?
rowid is a unique value assigned by system automatically when ever a insert statement gets successful.
rowid contains the address of data file,data block, object id, rownumber
------------------------------------------------------------------------------------------------------------
Q. What is the fastest way of accessing a row in a ta...
by using the index and rowid
------------------------------------------------------------------------------------------------------------
Q. What is an Integrity Constraint?
Integrity constraint restricts values of a column so that only meaningful values as per the business logic of the table be entered into the column.
Integrity constraints are of the following types:
Q. What is Referential Integrity ?
Foreign key constraints are known as referential integrity. Which refers to a primary or ( unique ,not null) column
------------------------------------------------------------------------------------------------------------
Q. What is the usage of SAVE POINTS?
save point is used to give some break points between multiple transactions so that if some transaction is required to be rolled back then some of transaction will still available in buffer. commit will save the data and remove all save points
------------------------------------------------------------------------------------------------------------
Q. What is ON DELETE CASCADE ?
When ON DELETE CASCADE is specified ORACLE maintains referential integrity by automatically removing dependent foreign key values if a referenced primary or unique key value is removed.
------------------------------------------------------------------------------------------------------------
Q. What is difference between CHAR and VARCHAR2 ...
FOR ORACLE 9I AND ABOVE.
CHAR CAN HAVE UPTO 2000 BUT FIX ( IT WILL TAKE 2000 Byies even used only 4 char)
varchar2 can have upto 4000 and variable size
------------------------------------------------------------------------------------------------------------
Q. How many LONG columns are allowed in a table ?
Only one LONG columns is allowed. It is not possible to use LONG column in WHERE or ORDER BY clause
------------------------------------------------------------------------------------------------------------
Q. What is a database link ?
Database Link is a named path through which a remote database can be accessed.
------------------------------------------------------------------------------------------------------------
Q. How to access the current value and next value from a sequence ? Is it possible to access the current value in a session before accessing next value ? Sequence name CURRVAL, Sequence name NEXTVAL. It is not possible. Only if you access next value in the session, current value can be accessed.
------------------------------------------------------------------------------------------------------------
Q. What is CYCLE/NO CYCLE in a Sequence ?
In a sequence if we use cycle:- the sequence will repeat after the last sequence number with the first sequence number.in a sequence if we use no cycle:-the sequence will not repeat and continue to upward state.
------------------------------------------------------------------------------------------------------------
Q. What are the advantages of VIEW ?
Advantages of view:
Q. Can a view be updated/inserted/deleted? If Yes under what
conditions?
Q. Which date function returns number value
months_between This date function takes 2 valid dates and returns number of months in between them.
------------------------------------------------------------------------------------------------------------
Q. What is the use of TNSNAME.ORA and LISTENER.ORA
listener is used to get the client server communication. You can access your server only if the listener is ON
------------------------------------------------------------------------------------------------------------
Q. What are the different tablespaces in database
Q: What is the maximum number of triggers, can apply to a single table
but u can write n number of trigger in a table.
Q.Difference between a View and Materialized View
Ans:
View is nothing but a set a sql statements together which join single or multiple tables and shows the data. however views do not have the data themselves but point to the data .
Whereas Materialized view is a concept mainly used in Datawarehousing . these views contain the data itself .Reason being it is easier/faster to access the data.The main purpose of Materialized view is to do calculations and display data from multiple tables using joins.
In view for every event on base tables view automatically update immediately,do not require seperate event to update it.Where as in M.view we can update for a certain period of time with certain methods called (Fast,force,never,complete all are update methods).
------------------------------------------------------------------------------------------------------------
Q.What are the various types of queries?
The types of queries are :
DDL
Data Definition Language (DDL) statements are used to define the database structure or schema. Some examples:
- CREATE - to create objects in the database
- ALTER - alters the structure of the database
- DROP - delete objects from the database
- TRUNCATE - remove all records from a table, including all spaces allocated for the records are removed
- COMMENT - add comments to the data dictionary
- RENAME - rename an object
Data Manipulation Language (DML) statements are used for managing data
within schema objects. Some examples:
------------------------------------------------------------------------------------------------------------
CURSOR
For every SQL statement execution a certain area in memory is allocated. PL/SQL allows you to name this area. This private SQL area is called context area or cursor. A cursor acts as a handler or pointer into the context area.
When you declare a cursor, you get a pointer variable, which does not point any thing. When the cursor is opened, memory is allocated and the cursor structure is created. The cursor variable now points the cursor. When the cursor is closed the memory allocated for the cursor is released.
Cursors allow the programmer to retrieve data from a table and perform actions on that data one row at a time. There are two types of cursors implicit cursors and explicit cursors.
Implicit cursors For SQL queries returning single row PL/SQL declares implicit cursors. Implicit cursors are simple SELECT statements and are written in the BEGIN block (executable section) of the PL/SQL. Implicit cursors are easy to code, and they retrieve exactly one row.
- SELECT - retrieve data from the a database
- INSERT - insert data into a table
- UPDATE - updates existing data within a table
- DELETE - deletes all records from a table, the space for the records remain
- MERGE - UPSERT operation (insert or update)
- CALL - call a PL/SQL or Java subprogram
- EXPLAIN PLAN - explain access path to data
- LOCK TABLE - control concurrency
- GRANT - gives user's access privileges to database
- REVOKE - withdraw access privileges given with the GRANT command
- COMMIT - save work done
- SAVEPOINT - identify a point in a transaction to which you can later roll back
- ROLLBACK - restore database to original since the last COMMIT
- SET TRANSACTION - Change transaction options like isolation level and what rollback segment to use
------------------------------------------------------------------------------------------------------------
Q.How many types of of joins are available in oracle?
Oracle 9i join syntax have four type of joining
Inner join/Equi Join - This type of join query compares each row of tab.A with each row of
tab.B to find all pairs of rows which satisfy the join-predicate. When the
join-predicate is satisfied, column values for each matched pair of rows
of A and B are combined into a result row.
Example:
We can write this in two ways as follows:
LEFT OUTER JOIN
FULL OUTER JOIN
Self join
A self join is a join in which a table is joined with
itself
SELECT e1.ename||' works for '||e2.ename "Employees and Managers"
- Oracle9i join syntax
- SQL1999 join syntax
Oracle 9i join syntax have four type of joining
- Equi join
- Non-equi Join
- Self Join
- Outer join
- Curtision products
- Natural Join
- Cross-join
- Using-on
- Using-with
- Inner join
- Outer join
Note: There is no functionality difference between Oracle9i join
syntax and SQL1999 join syntax.They have only syntax differences
Example:
We can write this in two ways as follows:
SELECT *
FROM employee
INNER JOIN department ON employee.DepartmentID =
department.DepartmentID;
SELECT *
SELECT *
FROM employee, department
WHERE employee.DepartmentID = department.DepartmentID;
Outer join - Outer join types are LEFT and RIGHT outer join and also FULL outer join
An outer join returns all rows that satisfy the join condition and also returns some or all of those rows from one table for which no rows from the other satisfy the join condition.
Outer join - Outer join types are LEFT and RIGHT outer join and also FULL outer join
An outer join returns all rows that satisfy the join condition and also returns some or all of those rows from one table for which no rows from the other satisfy the join condition.
LEFT OUTER JOIN
SELECT *
FROM A, B
WHERE A.column = B.column(+)
RIGHT OUTER JOIN
RIGHT OUTER JOIN
SELECT *
FROM A, B
WHERE B.column(+) = A.column
Note: Specifically, if the (+) is on the right, it's a LEFT JOIN. If (+) is on the left, it's a RIGHT JOIN. Don't get confuse
Note: Specifically, if the (+) is on the right, it's a LEFT JOIN. If (+) is on the left, it's a RIGHT JOIN. Don't get confuse
FULL OUTER JOIN
LEFT outer query
union
RIGHT ouetr query
Self join
FROM emp e1, emp e2
WHERE e1.mgr = e2.empno;
Cross/Cartesian join - CROSS JOIN returns rows which combine each row from the first table
with each row from the second table.Suppose you have 10 row from each
table it will give you tabA.10*tabB.10 rows in result output-multiply
the amount of rows.
CURSOR
For every SQL statement execution a certain area in memory is allocated. PL/SQL allows you to name this area. This private SQL area is called context area or cursor. A cursor acts as a handler or pointer into the context area.
When you declare a cursor, you get a pointer variable, which does not point any thing. When the cursor is opened, memory is allocated and the cursor structure is created. The cursor variable now points the cursor. When the cursor is closed the memory allocated for the cursor is released.
Cursors allow the programmer to retrieve data from a table and perform actions on that data one row at a time. There are two types of cursors implicit cursors and explicit cursors.
Implicit cursors For SQL queries returning single row PL/SQL declares implicit cursors. Implicit cursors are simple SELECT statements and are written in the BEGIN block (executable section) of the PL/SQL. Implicit cursors are easy to code, and they retrieve exactly one row.
PL/SQL implicitly declares cursors for all DML statements. The most commonly
raised exceptions here are NO_DATA_FOUND or TOO_MANY_ROWS.
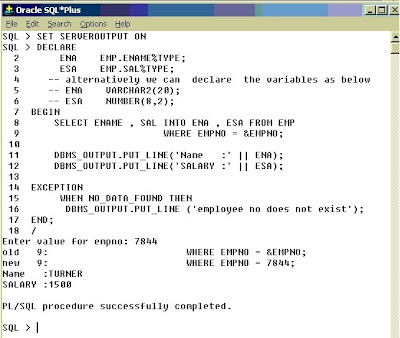
Syntax:
SELECT ename, sal INTO ena, esa FROM EMP WHERE EMPNO = 7844;
Note: Ename and sal are columns of the table EMP and ena and esa
are the variables used to store ename and sal fetched by the query.

Explicit Cursors
Explicit cursors are used in queries that return multiple rows. The set of rows fetched by a query is called active set. The size of the active set meets the search criteria in the select statement.
Explicit cursor is declared in the DECLARE section of PL/SQL program.
Syntax:
CURSOR <cursor-name> IS <select statement> ;
Sample Code:
DECLARE
CURSOR emp_cur IS
Explicit cursors are used in queries that return multiple rows. The set of rows fetched by a query is called active set. The size of the active set meets the search criteria in the select statement.
Explicit cursor is declared in the DECLARE section of PL/SQL program.
Syntax:
CURSOR <cursor-name> IS <select statement> ;
Sample Code:
DECLARE
CURSOR emp_cur IS
SELECT ename FROM EMP;
BEGIN
----
---
END;
User-defined explicit cursor needs to be opened, before reading the rows, after which it is closed.
Opening Cursor
Syntax: OPEN <cursor-name>;
Example: OPEN emp_cur;
When a cursor is opened the active set is determined, the rows satisfying the where clause in the select statement are added to the active set. A pointer is established and points to the first row in the active set.
Fetching from the cursor: To get the next row from the cursor we need to use fetch statement.
Syntax: FETCH <cursor-name> INTO <variables>;
Example: FETCH emp_cur INTO ena;
**FETCH statement retrieves one row at a time.
Closing the cursor: After retrieving all the rows from active set the cursor should be closed. Resources allocated for the cursor are now freed. Once the cursor is closed the execution of fetch statement will lead to errors.
CLOSE <cursor-name>;
Explicit Cursor Attributes
BEGIN
----
---
END;
User-defined explicit cursor needs to be opened, before reading the rows, after which it is closed.
Opening Cursor
Syntax: OPEN <cursor-name>;
Example: OPEN emp_cur;
When a cursor is opened the active set is determined, the rows satisfying the where clause in the select statement are added to the active set. A pointer is established and points to the first row in the active set.
Fetching from the cursor: To get the next row from the cursor we need to use fetch statement.
Syntax: FETCH <cursor-name> INTO <variables>;
Example: FETCH emp_cur INTO ena;
**FETCH statement retrieves one row at a time.
Closing the cursor: After retrieving all the rows from active set the cursor should be closed. Resources allocated for the cursor are now freed. Once the cursor is closed the execution of fetch statement will lead to errors.
CLOSE <cursor-name>;
Explicit Cursor Attributes
Every cursor defined by the user has 4 attributes. When appended to the
cursor name these attributes let the user access useful information about
the execution of a multirow query.
The attributes are:
- %NOTFOUND: It is a Boolean attribute, which evaluates to true, if the last fetch failed. i.e. when there are no rows left in the cursor to fetch.
- %FOUND: Boolean variable, which evaluates to true if the last fetch, succeeded.
- %ROWCOUNT: It’s a numeric attribute, which returns number of rows fetched by the cursor so far.
- %ISOPEN: A Boolean variable, which evaluates to true if the cursor is opened otherwise to false.

In above example I wrote a separate fetch for each row, instead loop
statement could be used here. Following example explains the usage of LOOP.
Using WHILE:
While LOOP can be used as shown in the following example for accessing the cursor values.
Example:
While LOOP can be used as shown in the following example for accessing the cursor values.
Example:

Fetch is used twice in the above example to make %FOUND available. See below
example.

Using Cursor For Loop:
The cursor for Loop can be used to process multiple records. There are two benefits with cursor for Loop.
- It implicitly declares a %ROWTYPE variable, also uses it as LOOP index
- Cursor For Loop itself opens a cursor, read records then closes the cursor automatically. Hence OPEN, FETCH and CLOSE statements are not necessary in it.

emp_rec is automatically created variable of %ROWTYPE. We have not used
OPEN, FETCH, and CLOSE in the above example as for cursor loop does it
automatically. The above example can be rewritten as shown in the Fig, with
less lines of code. It is called Implicit for Loop.

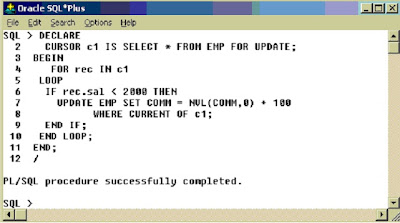
Deletion or Updating Using Cursor: In all the previous examples I explained about how to retrieve data using cursors. Now we will see how to modify or delete rows in a table using cursors. In order to Update or Delete rows, the cursor must be defined with the FOR UPDATE clause.
The Update or Delete statement must be declared with WHERE CURRENT OF
Following example updates comm of all employees with salary less than 2000 by adding 100 to existing comm.
Following example updates comm of all employees with salary less than 2000 by adding 100 to existing comm.

Explicit Cursors
There are three types of explicit cursor declarations
- A cursor without parameters, such as:
SELECT company_id FROM company;
- A cursor that accepts arguments through a parameter list:
SELECT name FROM company
WHERE company_id = id_in;
- A cursor header that contains a RETURN clause in place of the SELECT statement:
RETURN
company%ROWTYPE IS
SELECT * FROM company;
SYNTAX:
OPEN cursor_name [(argument [,argument ...])];
FETCH cursor_name INTO record_or_variable_list
CLOSE cursor_name;
Note:If you declare a cursor in a local anonymous, procedure, or function block, that cursor will automatically close when the block terminates.
Note:Package-based cursors must be closed explicitly, or they stay open for the duration of your session. Closing a cursor that is not open raises an INVALID CURSOR exception.
SELECT * FROM company;
SYNTAX:
OPEN cursor_name [(argument [,argument ...])];
FETCH cursor_name INTO record_or_variable_list
CLOSE cursor_name;
Note:If you declare a cursor in a local anonymous, procedure, or function block, that cursor will automatically close when the block terminates.
Note:Package-based cursors must be closed explicitly, or they stay open for the duration of your session. Closing a cursor that is not open raises an INVALID CURSOR exception.
Explicit cursor attributes
There are four attributes associated with cursors:
There are four attributes associated with cursors:
- ISOPEN
- FOUND
- NOTFOUND
- ROWCOUNT.
cursor_name%attribute
Implicit Cursors
Whenever a SQL statement is directly in the execution or exception section of a PL/SQL block, you are working with implicit cursors. These statements include INSERT, UPDATE, DELETE, and SELECT INTO statements. Unlike explicit cursors, implicit cursors do not need to be declared, OPENed, FETCHed, or CLOSEd.
SELECT statements handle the %FOUND and %NOTFOUND attributes differently from explicit cursors. When an implicit SELECT statement does not return any rows, PL/SQL immediately raises the NO_DATA_FOUND exception and control passes to the exception section. When an implicit SELECT returns more than one row, PL/SQL immediately raises the TOO_MANY_ROWS exception and control passes to the exception section.
Implicit cursor attributes are referenced via the SQL cursor. For example:
BEGIN
UPDATE activity SET last_accessed := SYSDATE
WHERE UID = user_id;
Implicit Cursors
Whenever a SQL statement is directly in the execution or exception section of a PL/SQL block, you are working with implicit cursors. These statements include INSERT, UPDATE, DELETE, and SELECT INTO statements. Unlike explicit cursors, implicit cursors do not need to be declared, OPENed, FETCHed, or CLOSEd.
SELECT statements handle the %FOUND and %NOTFOUND attributes differently from explicit cursors. When an implicit SELECT statement does not return any rows, PL/SQL immediately raises the NO_DATA_FOUND exception and control passes to the exception section. When an implicit SELECT returns more than one row, PL/SQL immediately raises the TOO_MANY_ROWS exception and control passes to the exception section.
Implicit cursor attributes are referenced via the SQL cursor. For example:
BEGIN
UPDATE activity SET last_accessed := SYSDATE
WHERE UID = user_id;
IF SQL%NOTFOUND THEN
INSERT INTO activity_log (uid,last_accessed)
INSERT INTO activity_log (uid,last_accessed)
VALUES (user_id,SYSDATE);
END IF
END;
Q. Cursor variable restrictions as follows:
END;
Q. Cursor variable restrictions as follows:
- Cursor variables cannot be declared in a package since they do not have a persistent state.
- You cannot use the FOR UPDATE clause with cursor variables
- You cannot assign NULLs to a cursor variable nor use comparison operators to test for equality, inequality, or nullity
- Neither database columns nor collections can store cursor variables
- You cannot use RPCs to pass cursor variables from one server to another
- Cursor variables cannot be used with the dynamic SQL built-in package DBMS_SQL.
Using the FOR UPDATE clause does not require you to actually make changes to
the data; it only locks he rows when opening the cursor. These locks are
released on the next COMMIT or ROLLBACK
SELECT ...
FROM ...
FOR UPDATE [OF column_reference] [NOWAIT];
where column_reference is a comma-delimited list of columns that appear in the SELECT clause. The NOWAIT keyword tells the RDBMS to not wait for other blocking locks to be released. The default is to wait forever.
Q. The WHERE CURRENT OF clause
FROM ...
FOR UPDATE [OF column_reference] [NOWAIT];
where column_reference is a comma-delimited list of columns that appear in the SELECT clause. The NOWAIT keyword tells the RDBMS to not wait for other blocking locks to be released. The default is to wait forever.
Q. The WHERE CURRENT OF clause
UPDATE and DELETE statements can use a WHERE CURRENT OF clause if they
reference a cursor declared FOR UPDATE. This syntax indicates that the
UPDATE or DELETE should modify the current row identified by the FOR UPDATE
cursor. The syntax is:
[UPDATE | DELETE ] ...
WHERE CURRENT OF cursor_name;
[UPDATE | DELETE ] ...
WHERE CURRENT OF cursor_name;
By using WHERE CURRENT OF, you do not have to repeat the WHERE clause in the
SELECT statement. For example:
DECLARE
CURSOR wip_cur IS
SELECT acct_no, enter_date FROM wip
WHERE enter_date < SYSDATE -7
FOR UPDATE;
BEGIN
FOR wip_rec IN wip_cur
LOOP
INSERT INTO acct_log (acct_no, order_date)
VALUES (wip_rec.acct_no, wip_rec.enter_date);
DECLARE
CURSOR wip_cur IS
SELECT acct_no, enter_date FROM wip
WHERE enter_date < SYSDATE -7
FOR UPDATE;
BEGIN
FOR wip_rec IN wip_cur
LOOP
INSERT INTO acct_log (acct_no, order_date)
VALUES (wip_rec.acct_no, wip_rec.enter_date);
DELETE FROM
wip
WHERE CURRENT OF wip_cur;
WHERE CURRENT OF wip_cur;
END LOOP;
END;
------------------------------------------------------------------------------------------------------------
Q. What is Data Concarency and Consistency?
Data Concarency => Means that many users can access data at the same time.
Data Consistency => Means that each user sees a consistent view of the data, including visible changes made by the user's own transactions and transactions of other users.
------------------------------------------------------------------------------------------------------------
Q. Is it possible to use Transaction control Statements such a ROLLBACK or COMMIT in Database trigger?
Generally In triggers you can't use TCL commands. But you can use TCL commands in Autonomous Triggers. You can declare a trigger as Autonomous by providing PRAGMA AUTONOMOUS_TRANSACTION in the beginning of the trigger. At a same time you have to end your trigger with commit/rollback. You can use these type of triggers to maintain log details of a table.
CREATE TRIGGER parts_trigger
BEFORE INSERT ON parts FOR EACH ROW
DECLARE
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
INSERT INTO parts_log VALUES(:new.pnum, :new.pname);
COMMIT; -- allowed only in autonomous triggers
END;
------------------------------------------------------------------------------------------------------------
END;
------------------------------------------------------------------------------------------------------------
Q. What is Data Concarency and Consistency?
Data Concarency => Means that many users can access data at the same time.
Data Consistency => Means that each user sees a consistent view of the data, including visible changes made by the user's own transactions and transactions of other users.
------------------------------------------------------------------------------------------------------------
Q. Is it possible to use Transaction control Statements such a ROLLBACK or COMMIT in Database trigger?
Generally In triggers you can't use TCL commands. But you can use TCL commands in Autonomous Triggers. You can declare a trigger as Autonomous by providing PRAGMA AUTONOMOUS_TRANSACTION in the beginning of the trigger. At a same time you have to end your trigger with commit/rollback. You can use these type of triggers to maintain log details of a table.
CREATE TRIGGER parts_trigger
BEFORE INSERT ON parts FOR EACH ROW
DECLARE
PRAGMA AUTONOMOUS_TRANSACTION;
BEGIN
INSERT INTO parts_log VALUES(:new.pnum, :new.pname);
COMMIT; -- allowed only in autonomous triggers
END;
------------------------------------------------------------------------------------------------------------
Q: What is an Exception ? What are types of exception available
in oracle?
Exceptions An Exception is an error situation, which arises during program execution.
When an error occurs exception is raised, normal execution is terminated and control transfers to exception-handling part. Exception handlers are routines written to handle the exception. The exceptions can be internally defined (system-defined or pre-defined) or User-defined exception.
Predefined exception is raised automatically whenever there is a violation of Oracle coding rules.
Predefined exceptions are those like ZERO_DIVIDE, which is raised automatically when we try to divide a number by zero. Other built-in exceptions are given below.
You can handle unexpected Oracle errors using OTHERS handler. It can handle all raised exceptions that are not handled by any other handler.
It must always be written as the last handler in exception block.
- CURSOR_ALREADY_OPEN – Raised when we try to open an already open cursor.
- DUP_VAL_ON_INDEX – When you try to insert a duplicate value into a unique column
- INVALID_CURSOR – It occurs when we try accessing an invalid cursor
- INVALID_NUMBER – On usage of something other than number in place of number value
- LOGIN_DENIED – At the time when user login is denied
- TOO_MANY_ROWS – When a select query returns more than one row and the destination variable can take only single value
- VALUE_ERROR – When an arithmetic, value conversion, truncation, or constraint error occurs
- NO_DATA_FOUND
- ZERO_DIVIDE
The biggest advantage of exception handling is it improves readability and reliability of the code. Errors from many statements of code can be handles with a single handler. Instead of checking for an error at every point we can just add an exception handler and if any exception is raised it is handled by that.
For checking errors at a specific spot it is always better to have those statements in a separate begin – end block.
Examples: Following example gives the usage of ZERO_DIVIDE exception

Example 2: I have explained the usage of NO_DATA_FOUND exception in
the following

The DUP_VAL_ON_INDEX is raised when a SQL statement tries
to create a duplicate value in a column on which a primary key or unique
constraints are defined.
Example to demonstrate the exception DUP_VAL_ON_INDEX
Example to demonstrate the exception DUP_VAL_ON_INDEX

.

More than one Exception can be written in a single handler as shown below.
EXCEPTION
When NO_DATA_FOUND or TOO_MANY_ROWS then
Statements;
END;
------------------------------------------------------------------------------------------------------------
User-defined Exceptions
A User-defined exception has to be defined by the programmer. User-defined exceptions are declared in the declaration section with their type as exception.
They must be raised explicitly using RAISE statement, unlike pre-defined exceptions that are raised implicitly. RAISE statement can also be used to raise internal exceptions.
Declaring Exception:
DECLARE
myexception EXCEPTION;
BEGIN
------
if not satisfy
Raising Exception:
goto exception block and handle the exception
BEGIN
RAISE myexception;
-------
Handling Exception:
BEGIN
------
----
EXCEPTION
WHEN myexception THEN
Statements;
END;
Points To Ponder:
EXCEPTION
When NO_DATA_FOUND or TOO_MANY_ROWS then
Statements;
END;
------------------------------------------------------------------------------------------------------------
User-defined Exceptions
A User-defined exception has to be defined by the programmer. User-defined exceptions are declared in the declaration section with their type as exception.
They must be raised explicitly using RAISE statement, unlike pre-defined exceptions that are raised implicitly. RAISE statement can also be used to raise internal exceptions.
Declaring Exception:
DECLARE
myexception EXCEPTION;
BEGIN
------
if not satisfy
Raising Exception:
goto exception block and handle the exception
BEGIN
RAISE myexception;
-------
Handling Exception:
BEGIN
------
----
EXCEPTION
WHEN myexception THEN
Statements;
END;
Points To Ponder:
- An Exception cannot be declared twice in the same block.
- Exceptions declared in a block are considered as local to that block and global to its sub-blocks
- An enclosing block cannot access Exceptions declared in its sub-block. Where as it possible for a sub-block to refer its enclosing Exceptions.
The following example explains the usage of User-defined Exception

- SQLCODE – Returns the numeric value for the error code
- SQLERRM – Returns the message associated with error number
------------------------------------------------------------------------------------------------------------
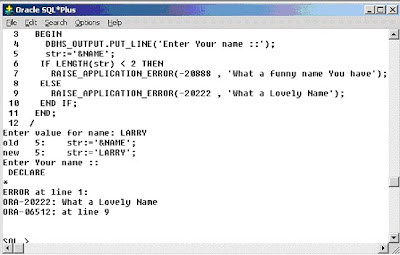
RAISE_APPLICATION_ERROR
To display your own error messages one can use the built-in RAISE_APPLICATION_ERROR.
They display the error message in the same way as Oracle errors. You should use a negative number between –20000 to –20999 for the error_number
And the error message should not exceed 512 characters.
The syntax to call raise_application_error is
RAISE_APPLICATION_ERROR (error_number, error_message, { TRUE | FALSE });
To display your own error messages one can use the built-in RAISE_APPLICATION_ERROR.
They display the error message in the same way as Oracle errors. You should use a negative number between –20000 to –20999 for the error_number
And the error message should not exceed 512 characters.
The syntax to call raise_application_error is
RAISE_APPLICATION_ERROR (error_number, error_message, { TRUE | FALSE });

DECLARE
num_tables NUMBER;
BEGIN
SELECT COUNT(*)
num_tables NUMBER;
BEGIN
SELECT COUNT(*)
INTO num_tables
FROM USER_TABLES;
IF num_tables < 1000 THEN
/*
Issue your own error code (ORA-20101) with your own error
message.
Note that you do not need to qualify raise_application_error with
DBMS_STANDARD */
DBMS_STANDARD */
raise_application_error(-20101, 'Expecting at least 1000
tables');
ELSE
NULL; -- Do the rest of the processing (for the non-error case).
NULL; -- Do the rest of the processing (for the non-error case).
END IF;
END;
------------------------------------------------------------------------------------------------------------
PRAGMA EXCEPTION_INIT (exception, error_number)
Pragma exception_init Allow you to handle the Oracle predefined message by you'r own message.
Means you can instruct compiler to associate the specific message to oracle predefined message at compile time.
This way you improve the Readability of your program, and handle it according to your own way.
You can use the pragma EXCEPTION_INIT to associate exception names with other Oracle error codes that you can handle OTHER exception block.
Within this handler, you can call the functions SQLCODE and SQLERRM to return the Oracle error code and message text. Once you know the error code, you can use it with pragma EXCEPTION_INIT and write a handler specifically for that error.
Example
END;
------------------------------------------------------------------------------------------------------------
PRAGMA EXCEPTION_INIT (exception, error_number)
Pragma exception_init Allow you to handle the Oracle predefined message by you'r own message.
Means you can instruct compiler to associate the specific message to oracle predefined message at compile time.
This way you improve the Readability of your program, and handle it according to your own way.
You can use the pragma EXCEPTION_INIT to associate exception names with other Oracle error codes that you can handle OTHER exception block.
Within this handler, you can call the functions SQLCODE and SQLERRM to return the Oracle error code and message text. Once you know the error code, you can use it with pragma EXCEPTION_INIT and write a handler specifically for that error.
Example
Using PRAGMA EXCEPTION_INIT
DECLARE
deadlock_detected EXCEPTION;
PRAGMA EXCEPTION_INIT(deadlock_detected, -60);
BEGIN
NULL; -- Some operation that causes an ORA-00060 error
EXCEPTION
WHEN deadlock_detected THEN
NULL; -- handle the error
END;
/
Example 2:
DECLARE
salary number;
FOUND_NOTHING exception;
Pragma exception_init(FOUND_NOTHING ,100);
BEGIN
select sal into salary
deadlock_detected EXCEPTION;
PRAGMA EXCEPTION_INIT(deadlock_detected, -60);
BEGIN
NULL; -- Some operation that causes an ORA-00060 error
EXCEPTION
WHEN deadlock_detected THEN
NULL; -- handle the error
END;
/
Example 2:
DECLARE
salary number;
FOUND_NOTHING exception;
Pragma exception_init(FOUND_NOTHING ,100);
BEGIN
select sal into salary
from emp
where ename ='ANURAG';
dbms_output.put_line(salary);
EXCEPTION
WHEN FOUND_NOTHING THEN
dbms_output.put_line(SQLERRM);
EXCEPTION
WHEN FOUND_NOTHING THEN
dbms_output.put_line(SQLERRM);
END;
Propagation of Exceptions
When an exception is raised and corresponding handler is not found in the current block then it propagates to the enclosing blocks till a handler is found. If a handler is not found in its enclosing blocks also then it raises an unhanded exception error to the host environment.
Exceptions cannot be propagated across remote procedure calls. i.e. a PL/SQL program cannot catch exceptions raised by remote subprograms
Re raising exceptions
When you want an exception to be handles in the current block as well in its enclosing block then you need to use RAISE statement without an exception name.
When an exception is raised and corresponding handler is not found in the current block then it propagates to the enclosing blocks till a handler is found. If a handler is not found in its enclosing blocks also then it raises an unhanded exception error to the host environment.
Exceptions cannot be propagated across remote procedure calls. i.e. a PL/SQL program cannot catch exceptions raised by remote subprograms
Re raising exceptions
When you want an exception to be handles in the current block as well in its enclosing block then you need to use RAISE statement without an exception name.

------------------------------------------------------------------------------------------------------------
Q: What do you know about sub-queries
SELECT id, first_name
FROM student_details
WHERE first_name IN (
FROM student_details
WHERE first_name IN (
SELECT first_name
FROM student_details
WHERE subject= 'Science'
FROM student_details
WHERE subject= 'Science'
);
Output:
id first_name
-------- -------------
100 Rahul
102 Stephen
In the above sql statement, first the inner query is processed first and then the outer query is processed.
Example: Insert statement sub-queries
Output:
id first_name
-------- -------------
100 Rahul
102 Stephen
In the above sql statement, first the inner query is processed first and then the outer query is processed.
Example: Insert statement sub-queries
Subquery can be used with INSERT statement to add rows of data from one or
more tables to another table. Lets try to group all the students who study
Maths in a table 'maths_group'.
INSERT INTO maths_group(id, name)
SELECT id, first_name || ' ' || last_name
FROM student_details WHERE subject= 'Maths'
A subquery can be used in the SELECT statement as follows. Lets use the product and order_items table defined in the sql_joins section.
select p.product_name, p.supplier_name, (
INSERT INTO maths_group(id, name)
SELECT id, first_name || ' ' || last_name
FROM student_details WHERE subject= 'Maths'
A subquery can be used in the SELECT statement as follows. Lets use the product and order_items table defined in the sql_joins section.
select p.product_name, p.supplier_name, (
select order_id from order_items where product_id = 101) as order_id
from product p where p.product_id = 101
Note: Sub-queries will be executed once for the entire parent statement
------------------------------------------------------------------------------------------------------------
Q. What is a correlated sub query
IF THE OUTPUT OF AN OUTER QUERY ACTS AS A INPUT TO THE INNER QUERY THEN THAT QUERY IS KNOW AS CORELATED SUB QUERY.
SELECT field1
Note: Sub-queries will be executed once for the entire parent statement
------------------------------------------------------------------------------------------------------------
Q. What is a correlated sub query
IF THE OUTPUT OF AN OUTER QUERY ACTS AS A INPUT TO THE INNER QUERY THEN THAT QUERY IS KNOW AS CORELATED SUB QUERY.
SELECT field1
from table1 X
WHERE field2>(
WHERE field2>(
select avg(field2) from table1 Y
where field1=X.field1
where field1=X.field1
);
------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------
Q. Different type of join used in sub-queries
Self join-Its a join foreign key of a table references the same table.
Outer Join--Its a join condition used where One can query all the
rows of one of the tables in the join condition even though they don't
satisfy the join condition.
Equi-join--Its a join condition that retrieves rows from one or more tables in which one or more columns in one table are equal to one or more columns in the second table.
------------------------------------------------------------------------------------------------------------
Q. In subqueries, which is efficient ,the IN clause or EXISTS clause? Does they produce the same result?
EXISTS is efficient because,
Equi-join--Its a join condition that retrieves rows from one or more tables in which one or more columns in one table are equal to one or more columns in the second table.
------------------------------------------------------------------------------------------------------------
Q. In subqueries, which is efficient ,the IN clause or EXISTS clause? Does they produce the same result?
EXISTS is efficient because,
- Exists is faster than IN clause
- IN check returns values to main query where as EXISTS returns Boolean (T or F)
Q. What is difference between TRUNCATE & DELETE ?
- Delete generates rollback segments, and its DML
- Truncate does not generate rollback segment and its DDL
- Once Truncate does not generate rollback so it’s faster then delete
- Truncate release the server space but delete doesn’t
- Truncate doesn't associate with any trigger,Delete does
- Truncate will reset High water mark,Delete doesn't
Q. Explain Connect by Prior ?
Retrieves rows in hierarchical order
------------------------------------------------------------------------------------------------------------
Q. Difference between SUBSTR and INSTR ?
substr is used to get a sub part of a string but instr is a function that returns the position of a specific character and also according to it's occurrence in that string
- INSTR (String1,String2(n,(m)),INSTR returns the position of the mth occurrence of the string 2 instring1. The search begins from nth position of string1
- SUBSTR (String1 n,m)SUBSTR returns a character string of size m in string1, starting from nth position of string1.
------------------------------------------------------------------------------------------------------------
Q. Explain UNION, MINUS, UNION ALL, INTERSECT?
- INTERSECT returns all distinct rows selected by both queries
- MINUS - returns all distinct rows selected by the first query but not by the second
- UNION - returns all distinct rows selected by either query
- UNION ALL - returns all rows selected by either query, including all duplicates.
Q. What is ROWID ?
rowid is a unique value assigned by system automatically when ever a insert statement gets successful.
rowid contains the address of data file,data block, object id, rownumber
------------------------------------------------------------------------------------------------------------
Q. What is the fastest way of accessing a row in a ta...
by using the index and rowid
------------------------------------------------------------------------------------------------------------
Q. What is an Integrity Constraint?
Integrity constraint restricts values of a column so that only meaningful values as per the business logic of the table be entered into the column.
Integrity constraints are of the following types:
- Not null
- Unique
- Primary Key
- Foreign Key (referential integrity)
- Check -- custom constraints e.g. check sal > 0, check joiningdate > date()
Q. What is Referential Integrity ?
Foreign key constraints are known as referential integrity. Which refers to a primary or ( unique ,not null) column
------------------------------------------------------------------------------------------------------------
Q. What is the usage of SAVE POINTS?
save point is used to give some break points between multiple transactions so that if some transaction is required to be rolled back then some of transaction will still available in buffer. commit will save the data and remove all save points
------------------------------------------------------------------------------------------------------------
Q. What is ON DELETE CASCADE ?
When ON DELETE CASCADE is specified ORACLE maintains referential integrity by automatically removing dependent foreign key values if a referenced primary or unique key value is removed.
------------------------------------------------------------------------------------------------------------
Q. What is difference between CHAR and VARCHAR2 ...
FOR ORACLE 9I AND ABOVE.
CHAR CAN HAVE UPTO 2000 BUT FIX ( IT WILL TAKE 2000 Byies even used only 4 char)
varchar2 can have upto 4000 and variable size
------------------------------------------------------------------------------------------------------------
Q. How many LONG columns are allowed in a table ?
Only one LONG columns is allowed. It is not possible to use LONG column in WHERE or ORDER BY clause
------------------------------------------------------------------------------------------------------------
Q. What is a database link ?
Database Link is a named path through which a remote database can be accessed.
------------------------------------------------------------------------------------------------------------
Q. How to access the current value and next value from a sequence ? Is it possible to access the current value in a session before accessing next value ? Sequence name CURRVAL, Sequence name NEXTVAL. It is not possible. Only if you access next value in the session, current value can be accessed.
------------------------------------------------------------------------------------------------------------
Q. What is CYCLE/NO CYCLE in a Sequence ?
In a sequence if we use cycle:- the sequence will repeat after the last sequence number with the first sequence number.in a sequence if we use no cycle:-the sequence will not repeat and continue to upward state.
------------------------------------------------------------------------------------------------------------
Q. What are the advantages of VIEW ?
Advantages of view:
- Restricts the access to particular columns and rows of the base tables
- Store complex queries.
- Hide the data complexity
- Can access the data for two different base tables with out performing a join
- Can display the data in different form from the base tables.(i.e. In the column names can can be changed with effecting the column names of the base tables).
------------------------------------------------------------------------------------------------------------
- View can be update/insert/delete if it contain fields of one table
- primary key should contain in select clause used for view
- but again if select statement used in view contains group by clause then we cant update view
- If select clause contains more than one tables then we can use instead of trigger for DMLoperations.
Q. Which date function returns number value
months_between This date function takes 2 valid dates and returns number of months in between them.
------------------------------------------------------------------------------------------------------------
Q. What is the use of TNSNAME.ORA and LISTENER.ORA
listener is used to get the client server communication. You can access your server only if the listener is ON
------------------------------------------------------------------------------------------------------------
Q. What are the different tablespaces in database
- Locally Managed Tablespaces
- Dictionary Managed Tablespaces
- System Tablespace
- Temporary Tablespace
Q: What is the maximum number of triggers, can apply to a single table
- Insert/Update/Delete :- 3
- Before/After:- 2
- Row Level/Statement Level:-2
but u can write n number of trigger in a table.
------------------------------------------------------------------------------------------------------------
Q.Difference between a View and Materialized View
Ans:
View is nothing but a set a sql statements together which join single or multiple tables and shows the data. however views do not have the data themselves but point to the data .
Whereas Materialized view is a concept mainly used in Datawarehousing . these views contain the data itself .Reason being it is easier/faster to access the data.The main purpose of Materialized view is to do calculations and display data from multiple tables using joins.
In view for every event on base tables view automatically update immediately,do not require seperate event to update it.Where as in M.view we can update for a certain period of time with certain methods called (Fast,force,never,complete all are update methods).
------------------------------------------------------------------------------------------------------------
Q.What are the various types of queries?
The types of queries are :
- Normal Queries
- Sub Queries
- Co-related queries
- Nested queries
- Compound queries
------------------------------------------------------------------------------------------------------------
Q. Difference between Truncate and delete?
To be continued Part-2
Q. Difference between Truncate and delete?
- Truncate is DDL where as Delete is DML
- Truncate can't be rollback in other hand delete can be rollback
- We can use WHERE clause in delete but not in truncate
- Trigger doesn't get fire in truncate but delete it is
- Truncate faster than delete, truncate releases space delete does not
- Truncate does affect high water mark level but delete does not.
- In delete you can use on delete cascade in case foreign key constraint where as truncate does not work if table has any foreign key constraint in it
- Drop delete data as well as structure and truncate only remove data
- Both are DDL
- It entirely remove table from Data dictionary but truncate doesn't
Q. Difference between In and Exists?
According to oracle document -- If the selective predicate is in the subquery, then use IN.
- If the selective predicate is in the parent query, then use EXISTS.
- if the subquery produced a relatively small result set, you should use IN subquery rather and an EXISTS subquery.
- Result of the subquery is "huge" and takes a long time, outer query is small. Then EXISTS is good to use.
- EXISTS is efficient on distinct data set
- If the result of sub query is small, and outer query is big then IN is good option
Note: If both query has huge data and in that case it depends on other
factor as well like index.rebuilding etc.Then in that case one should
try both option and require to check which one is better for his query,
make take some trace to identify better choice.
Q. Difference between where and having clause?
- WHERE clause select rows before group by clause and the HAVING is opposite in nature.
- WHERE clause can't contain aggregate function where as Having can.
- WHERE clause is used to filter records and HAVING is used for aggregate functions.
- HAVING clause can be used with GROUP BY function where as WHERE clause cannot be used with group by function.
Q. Difference between UNION and UNION ALL?
- Union sorts the set and remove the duplicate where as Union all doesn't sort and doesn't remove duplicate
- Union All faster than Union as it doesn't require sort functionality distinct the data set
------------------------------------------------------------------------------------------------------------
To be continued Part-2
Comments
Post a Comment
If you have any doubt let me know